You Only Look One-level Feature(YOLOF): Dissecting FPNs
Mar 27, 2022
Feature pyramids have become a vital part of state-of-the-art object detection models. The most prevalent method for creating feature pyramids is the feature pyramid network (FPN). FPNs have two main benefits:
- Multi-scale feature fusion: Fusing multiple high-resolution and low-resolution features to generate better object representations
- Divide-and-conquer: Using different feature levels to detect objects with varying scales
The general perception is that the success of FPNs relies heavily on the fusion of multiple-level features, and there have been multiple studies that build upon the idea. On the other hand, the divide-and-conquer function of FPNs has been largely overlooked. The authors of You Only Look One-level Feature, YOLOF, studied the influence of FPN’s two benefits individually. To do so they designed experiments that decoupled the multi-scale feature fusion and the divide-and-conquer functionalities with RetinaNet.
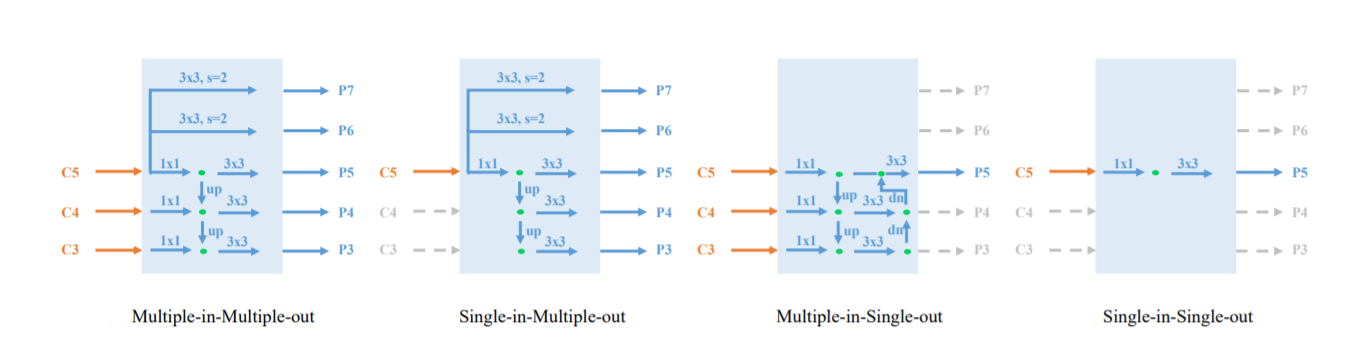
Detailed Structures of Multiple-in-Multiple-out (MiMo), Single-in-Multiple-out (SiMo), Multiple-in-Single-out (MiSo), and Single-in-Single-out (SiSo) encoders.
FPN was treated as a Multiple-in-Multiple-out (MiMo) encoder that encodes multi-scale features and provides feature representations for detection heads. In a controlled comparison among Multiple-in-Multiple-out (MiMo), Single-in-Multiple-out (SiMo), Multiple-in-Single-out (MiSo), and Single-in-Single-out (SiSo) encoders, the SiMo encoder achieved comparable performance with the MiMo encoder. This is surprising because SiMo encoders only have one input feature C5 and don’t perform feature fusion, the performance gap is less than 1 mAP. There is a significant drop in performance drops (≥ 12 mAP) for MiSo and SiSo encoders.
These findings suggest two things:
- The C5 feature has adequate context for detecting objects on various scales, enabling the SiMo encoder to achieve comparable results
- The multi-scale feature fusion benefit of PFNs is far away less critical than the divide-and-conquer benefit.
With all its benefits, FPN also brings network complexity and memory burdens. It slows down the detectors drastically. Building on the findings of the encoder comparison, the authors came up with a simple but highly efficient model that doesn’t use FPN to address the optimization problem — YOLOF.
Architecture & Approach
YOLOF uses a straightforward and efficient framework with single-level features. It can be broken down into three parts: the backbone, the encoder, and the decoder
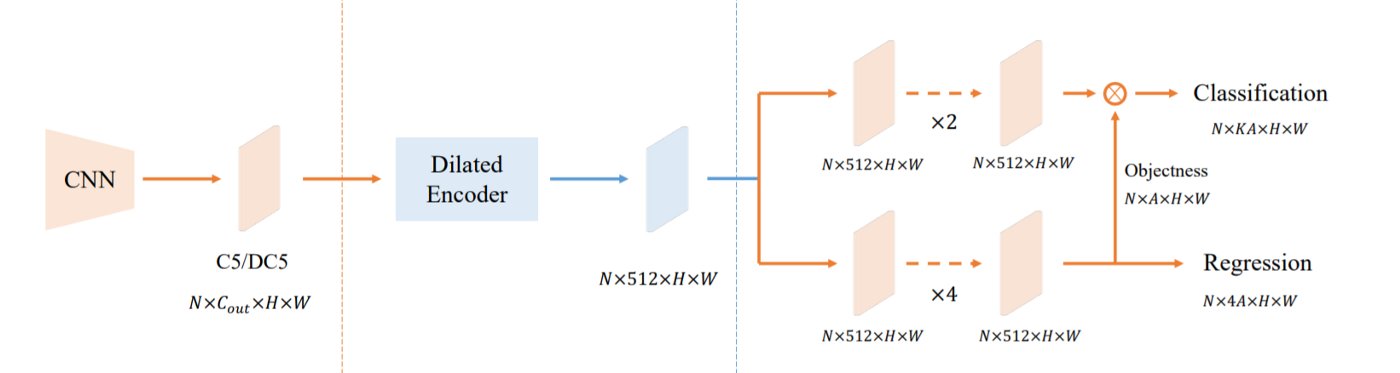
The sketch of YOLOF, which consists of three main components: the backbone, the encoder, and the decoder.
Backbone
YOLOF adopts the ResNet and ResNeXt series pre-trained on ImageNet as the backbone. The backbone outputs the C5 feature map with 2048 channels and a down-sample rate of 32. To make the comparison with other detectors the authors of YOLOF froze all the batch-norm layers in the backbone.
Encoder
Taking inspiration from FPN, the YOLOF encoder adds two projection layers — one 1 × 1 and one 3 × 3 convolution — after the backbone. This creates a feature map with 512 channels. Furthermore, residual blocks are added to enable the encoder’s output features to cover objects on different scales. These residual blocks consist of three convolutions: a 1 × 1 convolution with a channel reduction rate of 4, then a 3 × 3 convolution with dilation is used to enlarge the receptive field, and finally, a 1 × 1 convolution is used to recover the number of channels.
Decoder
The decoder adopts a slightly modified design of RetinaNet consisting of two parallel task-specific heads: the classification head and the regression head. The first modification is that the number of convolutions layers in the two heads are different: the regression head has four convolutions followed by batch normalization layers and ReLU layers while the classification head only has two. The second is the use of Autoassign to add an implicit objectness prediction for each anchor on the regression head. The classification output is multiplied by the corresponding implicit objectness to obtain the final classification scores for all predictions.
Other Implementation Details
The pre-defined anchors in YOLOF are sparse, this results in a decrease in the match quality between anchors and ground-truth boxes. To circumvent this issue the authors added a random shift operation on the image. This operation shifts the image randomly with a maximum of 32 pixels. The idea is to inject noise into the object’s position in the image, this increases the probability of ground-truth boxes matching with high-quality anchors. Furthermore, a restriction is applied to the anchors’ center’s shift.
Results
To establish the efficacy of this new simpler approach to object detection, YOLOF was compared to RetinaNet, DETR, and YOLOv4.
RetinaNet
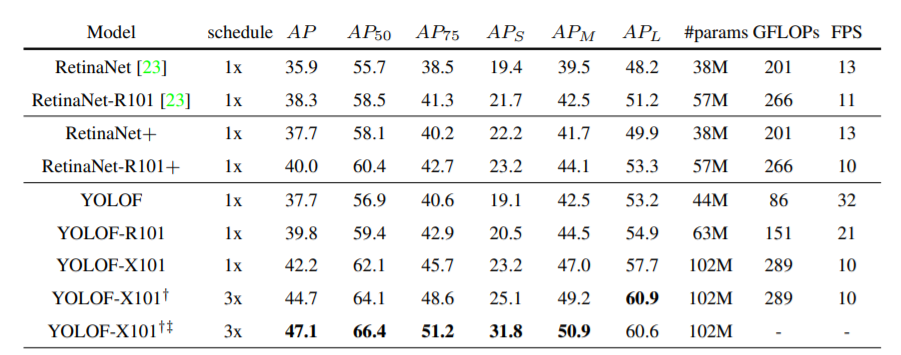
Comparison with RetinaNet on the COCO2017 validation set
YOLOF achieves results on par with RetinaNet+ with a 57% flops reduction and a 2.5 × speed up. YOLOF has an inferior performance (−3.1) than RetinaNet+ on small objects due to the large stride (32) of the C5 feature. However, YOLOF achieves better performance on large objects (+3.3)because of the dilated residual blocks in the encoder.
DETR
Much like YOLOF, DETR only uses a single C5 feature. It has achieved comparable results with a multi-level feature detector like Faster R-CNN. But the general consensus is that layers that capture global dependencies such as transformer layers are needed to achieve promising results in single-level feature detection.
![]()
Comparison with DETR on the COCO2017 validation set
However, YOLOF demonstrates that a conventional network with local convolution layers can also achieve this goal. It matches the DETR’s performance and gets more benefits from deeper networks than DETR. Interestingly, YOLOF outperforms DETR on small objects (+1.9 and +2.4) while lags behind DETR on large objects (-3.5 and -2.9). More importantly, compared with DETR, YOLOF converge much faster, almost 7 times faster.
YOLOv4

Comparison with YOLOv4 on the COCO test-dev set
YOLOF-DC5 runs 13% faster than YOLOv4 with a 0.8 mAP improvement on overall performance. Although YOLOFDC5 achieves less competitive results on small objects than YOLOv4 (24.0 mAP vs. 26.7 mAP), it outperforms on large objects by a large margin (+7.1 mAP).
Even with its stellar performance against its counterparts, YOLOF can’t hold a candle to YOLOR or YOLOX. YOLOR remains the clear winner in terms of performance and inference speed, YOLOX is a close second. Then there’s YOLOF and YOLOv4 that offer comparable performance, followed closely by YOLOv5.
All in all, these results indicate that single-level detectors have great potential to achieve state-of-the-art speed and accuracy simultaneously. YOLOF is an idea in its infancy, it will serve as a solid baseline and provide further insight for designing single-level feature detectors in future research.

Do you want to learn one of the most pivotal computer vision tasks — object detection — and convert it into a marketable skill by making cool applications like the one shown above? Enroll in our YOLOR course HERE today! It is a comprehensive course on YOLOR that covers not only the state-of-the-art YOLOR model and object detection fundamentals, but also the implementation of various use-cases and applications, as well as integrating models with a web UI for deploying your own YOLOR web apps.

Stay connected with news and updates!
Join our newsletter to receive the latest news and updates from our team.
Don't worry, your information will not be shared.
We hate SPAM. We will never sell your information, for any reason.

![AI In Agriculture [NEW]](https://kajabi-storefronts-production.kajabi-cdn.com/kajabi-storefronts-production/file-uploads/themes/2153492442/settings_images/f3fdf8-e3fc-6bce-d26-2adc20ba5c0a_1e6bab8-d7b-d76c-e28c-fa6d513e45d_7138c16-f641-8fdf-e206-2bcac503bc5_AI_AGRI.webp)


