Overcoming Challenges in Object Detection: Accuracy, Speed, and Scalability
Jul 07, 2023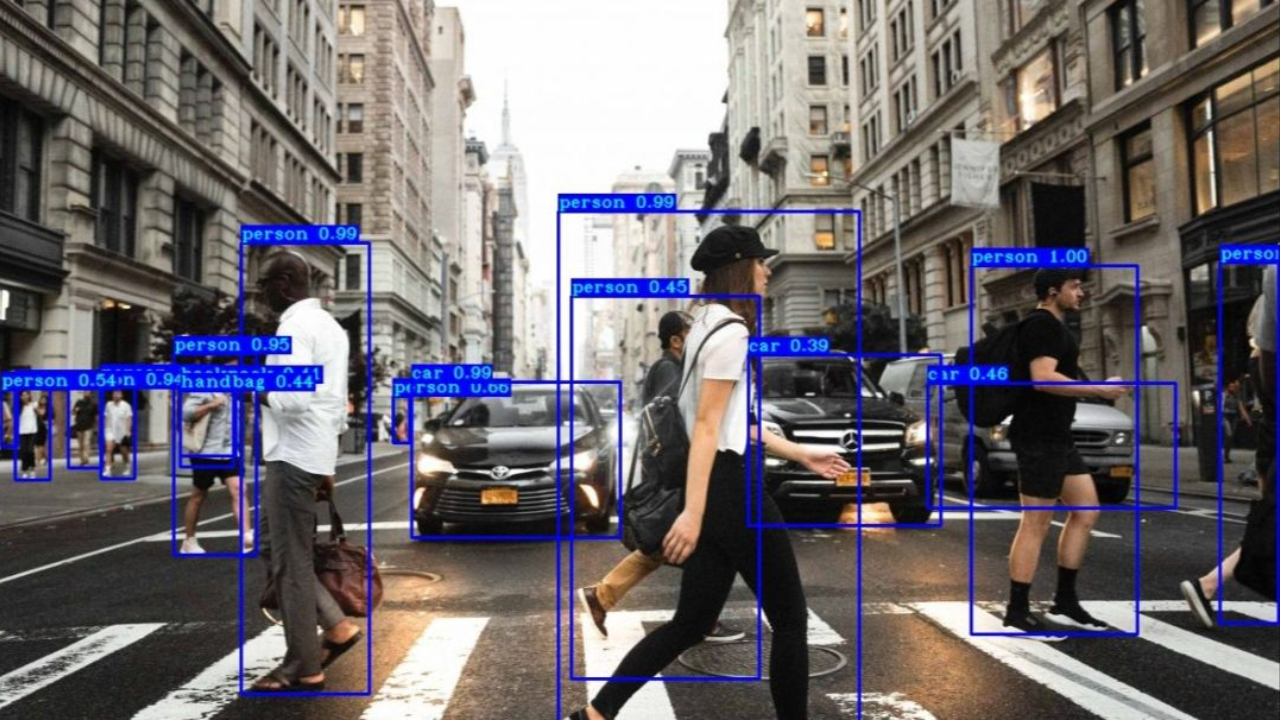
Object detection is a crucial task in the field of computer vision, enabling machines to identify and locate objects within images or videos. It has numerous applications, ranging from autonomous driving and surveillance systems to image recognition and augmented reality. However, there are several challenges that researchers and developers face when working on object detection systems. In this article, we will discuss the key challenges associated with accuracy, speed, and scalability in object detection and explore potential solutions to overcome them.
Introduction
Object detection plays a pivotal role in numerous computer vision applications, enabling machines to identify and locate objects in images or videos. The primary goal of object detection is to accurately classify and localize objects within a given scene. However, achieving high levels of accuracy, real-time performance, and scalability poses significant challenges.
In recent years, deep learning techniques, especially convolutional neural networks (CNNs), have revolutionized the field of object detection. Deep learning models have demonstrated remarkable performance in terms of accuracy and have surpassed traditional computer vision approaches. However, several challenges remain, including the trade-off between speed and accuracy, handling complex scenes with occlusions and cluttered backgrounds, scale and perspective variations, object class imbalance, and achieving real-time performance on resource-constrained devices.

The Trade-Off Between Speed and Accuracy
One of the fundamental challenges in object detection is the trade-off between speed and accuracy. Traditional two-stage object detectors, such as the region-based convolutional neural network (R-CNN) family, achieve high accuracy by performing region proposal and object classification in separate stages. However, this approach is computationally expensive and leads to slower inference times.
On the other hand, single-stage object detectors, such as the You Only Look Once (YOLO) family, trade off some accuracy for faster inference speeds. These models directly predict object bounding boxes and class probabilities from a single pass through the network. While single-stage detectors are faster, they may struggle with detecting small objects and accurately localizing objects with overlapping bounding boxes.
Single-Stage Object Detectors
Single-stage object detectors, exemplified by the YOLO family, have gained popularity due to their real-time performance capabilities. These detectors divide the input image into a grid and assign responsibility for detecting objects to individual grid cells. However, single-stage detectors face challenges when dealing with small objects, as they may be overwhelmed by the background context or have limited spatial resolution to capture fine-grained details.
Two-Stage Object Detectors
Two-stage object detectors, such as Faster R-CNN and Mask R-CNN, have traditionally achieved state-of-the-art accuracy by employing a region proposal network (RPN) to generate object proposals. These detectors excel at accurately localizing objects and handling complex scenes with occlusions. However, the multi-stage architecture and the need for region proposal generation make them computationally expensive and slower compared to single-stage detectors.
YOLO: A Game-Changing Approach
The YOLO (You Only Look Once) series of object detectors introduced a groundbreaking approach to object detection. YOLO models achieve real-time performance by directly predicting object bounding boxes and class probabilities from a single pass through the network. They use a single unified architecture to simultaneously predict objects at multiple scales and achieve impressive speed-accuracy trade-offs. YOLO models have become popular in applications that require real-time object detection, such as autonomous driving and video surveillance systems.

Challenges in Object Detection Accuracy
a. Occlusion and Cluttered Backgrounds
Objects in real-world scenarios are often partially occluded or surrounded by cluttered backgrounds, making accurate detection challenging. Occlusion occurs when objects are hidden or obscured by other objects in the scene, leading to incomplete or fragmented visual information. Cluttered backgrounds introduce additional complexity, as objects may blend with their surroundings, making it difficult to distinguish them accurately.
b. Scale and Perspective Variations
Objects can appear at different scales and orientations in images, requiring detectors to handle scale and perspective variations effectively. Small objects pose a challenge as they may have limited visual information and can be easily overwhelmed by the background. Conversely, large objects may exhibit variations in shape and appearance, making accurate detection more complex.
c. Object Class Imbalance
Object detection datasets often suffer from class imbalance, where certain object classes are overrepresented while others have limited samples. Class imbalance can impact the learning process, leading to biased models that prioritize frequent classes. Achieving robust performance across all object classes requires addressing this imbalance and designing appropriate loss functions and sampling strategies.
Challenges in Object Detection Speed
a. Real-Time Object Detection
Real-time object detection is essential in applications that require immediate responses, such as autonomous driving or video surveillance. Achieving real-time performance, typically defined as processing at least 30 frames per second (FPS), is challenging due to the computational demands of deep learning models. Efficient algorithms, hardware acceleration, and model optimization techniques are crucial to meet real-time requirements.
b. Efficient Hardware Utilization
Utilizing hardware resources efficiently is vital for achieving high-performance object detection. GPUs and specialized hardware accelerators, such as TPUs and FPGAs, can significantly speed up inference. However, efficiently mapping the computational workload onto these devices and optimizing memory access patterns is essential for maximizing hardware utilization and achieving fast inference times.
c. Optimized Algorithms
Algorithmic optimizations play a crucial role in improving object detection speed. Techniques such as network pruning, quantization, and knowledge distillation can reduce model complexity and computational requirements without significant accuracy degradation. Additionally, leveraging model parallelism and distributed computing can further enhance inference speed by parallelizing computations across multiple devices.

Challenges in Object Detection Scalability
a. Handling Large Datasets
Training object detection models often requires large annotated datasets, which can be challenging to collect and label. Handling large datasets efficiently, including storage, preprocessing, and distributed training, is essential for scalability. Techniques like data augmentation, transfer learning, and semi-supervised learning can help mitigate the need for extensive labeled data while maintaining performance.
b. Distributed Computing for Training
Training deep learning models for object detection can be computationally intensive, requiring significant computational resources. Distributed computing frameworks, such as TensorFlow and PyTorch, enable distributed training across multiple machines or GPUs, improving training speed and scalability. Efficient synchronization and communication between devices are critical to achieving efficient distributed training.
c. Deployment on Edge Devices
Object detection models are often deployed on edge devices with limited computational resources, such as drones, surveillance cameras, or mobile devices. Ensuring efficient and lightweight models that can run in real-time on these devices is a significant scalability challenge. Model compression techniques, quantization, and hardware acceleration can help optimize models for edge deployment.
Conclusion
Object detection is a vital task in computer vision with various challenges related to accuracy, speed, and scalability. Achieving high accuracy while maintaining real-time performance and scalability is an ongoing research area. Researchers have proposed innovative algorithms, architectures, and optimization techniques to address these challenges and push the boundaries of object detection.
Object detection models must tackle challenges such as occlusion, scale variations, and object class imbalance to improve accuracy. Speed challenges require efficient algorithms, hardware utilization, and optimization techniques to achieve real-time performance. Scalability challenges involve handling large datasets, distributed training, and deploying models on edge devices.
As the field of object detection continues to evolve, addressing these challenges will contribute to more robust and efficient object detection systems, enabling a wide range of applications across industries.
Ready to up your computer vision game? Are you ready to harness the power of YOLO-NAS in your projects? Don't miss out on our upcoming YOLOv8 course, where we'll show you how to easily switch the model to YOLO-NAS using our Modular AS-One library. The course will also incorporate training so that you can maximize the benefits of this groundbreaking model. Sign up HERE to get notified when the course is available: https://www.augmentedstartups.com/YOLO+SignUp. Don't miss this opportunity to stay ahead of the curve and elevate your object detection skills! We are planning on launching this within weeks, instead of months because of AS-One, so get ready to elevate your skills and stay ahead of the curve!

FAQs
A1: One-stage object detectors, such as YOLO, directly predict object bounding boxes and class probabilities from a single pass through the network. They offer real-time performance but may sacrifice some accuracy. Two-stage object detectors, like Faster R-CNN, employ a region proposal network (RPN) to generate object proposals and then refine them. They achieve higher accuracy but are computationally more expensive.
A2: Challenges in object detection accuracy include occlusion and cluttered backgrounds, scale and perspective variations, and object class imbalance. Occlusion and clutter can hide or obscure objects, making accurate detection difficult. Scale and perspective variations require models to handle objects at different sizes and orientations. Object class imbalance can lead to biased models that prioritize frequent classes.
A3: Object detection models can achieve real-time performance by leveraging efficient algorithms, hardware acceleration, and model optimization techniques. Techniques like network pruning, quantization, and knowledge distillation reduce model complexity. Hardware accelerators, such as GPUs, TPUs, and FPGAs, speed up inference. Parallel computing and distributed training further enhance performance.
A4: Deploying object detection models on edge devices involves addressing challenges such as limited computational resources and real-time performance requirements. Model compression techniques, quantization, and hardware acceleration optimize models for edge deployment. Lightweight architectures and efficient memory access patterns enable real-time inference on edge devices.
A5: Researchers handle large datasets in object detection through techniques like data augmentation, transfer learning, and semi-supervised learning. Data augmentation artificially increases the diversity of the dataset by applying transformations to existing samples. Transfer learning leverages pre-trained models on large-scale datasets to initialize object detection models. Semi-supervised learning utilizes both labeled and unlabeled data to improve performance.
Stay connected with news and updates!
Join our newsletter to receive the latest news and updates from our team.
Don't worry, your information will not be shared.
We hate SPAM. We will never sell your information, for any reason.

![AI In Agriculture [NEW]](https://kajabi-storefronts-production.kajabi-cdn.com/kajabi-storefronts-production/file-uploads/themes/2153492442/settings_images/f3fdf8-e3fc-6bce-d26-2adc20ba5c0a_1e6bab8-d7b-d76c-e28c-fa6d513e45d_7138c16-f641-8fdf-e206-2bcac503bc5_AI_AGRI.webp)


